

High-Performance Computing
A Balancing Act
The speed at which technology has advanced is astonishing, with computer hardware getting ever faster cores and smaller parts, and the availability of computational resources rapidly expanding. In CFD, high-performance computing (HPC) offers a host of benefits. It enables the execution of larger, more complex simulations, enhancing accuracy and giving engineers greater insight into various systems. HPC also drives productivity by reducing runtime and increasing throughput.
As hardware progresses, so must software. At Convergent Science, we stand at the leading edge of innovative technologies by ensuring the reliability and scalability of our CONVERGE CFD software.
Leveraging the Cutting Edge
Convergent Science employs a team of HPC experts dedicated to improving the performance of CONVERGE on the latest computing hardware. In addition, we collaborate with various national laboratories and industry partners, including Argonne National Laboratory, Hewlett Packard Enterprise, Intel, AMD, Oracle, Google, and NVIDIA, to ensure CONVERGE scales well on many cores. Through our extensive partnerships, we also implement support for various MPI packages and CPU architectures to test CONVERGE on different HPC systems.
Simply running cases on a larger number of cores doesn’t always lead to a significant speedup; the code’s parallelization algorithm must also efficiently handle load balancing. To guarantee CONVERGE scales linearly on thousands of cores, parallelization is accomplished through cell-based load balancing, i.e., on a cell-by-cell basis. Since each cell can theoretically belong to any processor, there is a greater deal of flexibility in how the cells are distributed, and users need not worry about their embedding levels. When the load balancing itself is performed in parallel, the simulation startup is significantly accelerated.
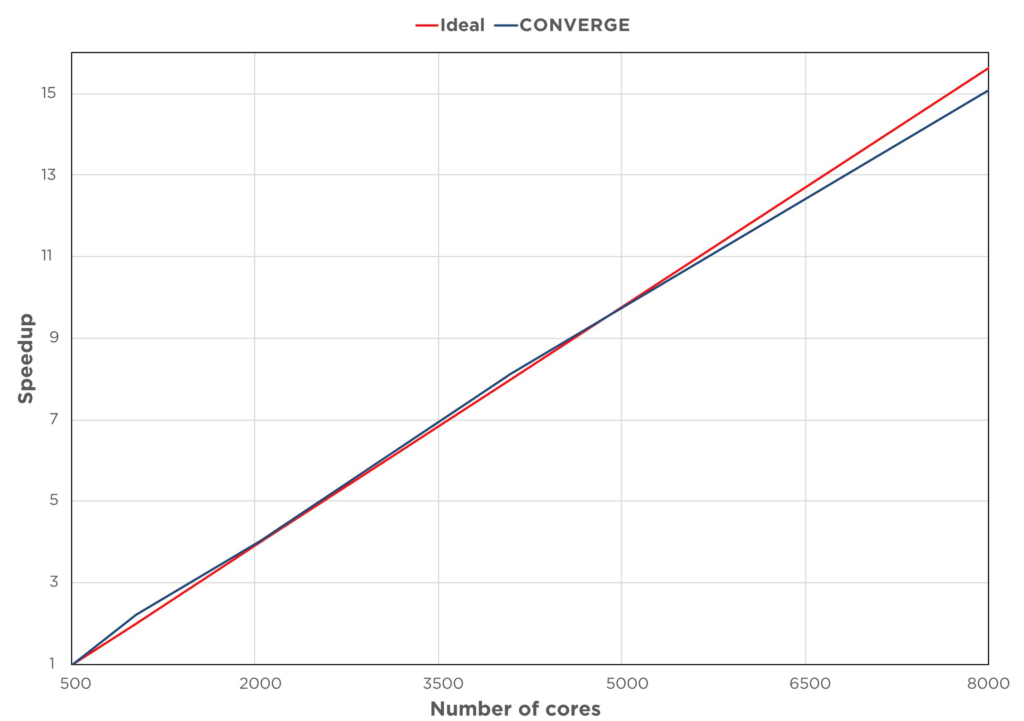
Increased Capability, Increased Capacity
While small CFD simulations can be executed in serial on a local machine in a reasonable amount of time, larger simulations often require a cluster of servers running in parallel to achieve acceptable runtimes without sacrificing accuracy. To address these different needs, we launched CONVERGE Horizon, a cloud computing service that allows you to run larger and more cost-effective simulations. Our collaboration with Oracle Cloud Infrastructure (OCI) allows CONVERGE Horizon users to access OCI’s high-tech bare metal servers and virtual machines on-demand at a discounted price. Additionally, CONVERGE Horizon users have access to CONVERGE on demand, allowing them to pay only for the software they need.
In one of the largest CONVERGE simulations to date, we were able to simulate a turbulent methane flame with a staggering 6 billion grid points on CONVERGE Horizon. The setup consisted of 100 Intel nodes, which is equal to 3,400 active compute cores. Memory usage was about 32 terabytes, and the simulation was post-processed using ParaView Catalyst, an in situ post-processing tool that allows you to analyze and visualize your data while the simulation is running.
While CONVERGE Horizon is an exceptionally versatile tool, CONVERGE users also have the option of outsourcing their simulations to all major cloud providers for highly parallel CFD simulations.
HPC at Work
Greater access to computational resources enables the execution of larger simulations and the exploration of more complex phenomena, which provides benefits across a wide range of applications.
For one, gas turbine simulations often contain hundreds of millions of cells. Running these cases on a low number of cores results in extremely long runtimes, which can be unacceptable for fast-paced industry timelines and makes repetitive testing impractical. With thousands of cores, however, you can obtain results in a much more reasonable timeframe, even for massive cases.
Given the high stakes of rocket launches, rocket engines must be flawless before being cleared for flight. As such, multiple rounds of testing should be completed for all propulsion components. Simulations need to be run to optimize predicted trajectories, engine thermodynamics, chemical reactions, heat transfer, fuel efficiency, and more. HPC allows engineers to explore many design iterations—facilitated by CONVERGE’s autonomous meshing—helping them identify and mitigate risks and potential complications before the actual launch.
For internal combustion engines, with sufficient computational resources, you can run multiple engine cycles in a day for quick turnaround on geometry optimization, emissions studies, cyclic variability analysis, predictive maintenance, and real-time analysis. By running CONVERGE on hundreds of cores, you can simulate more than 12 engine cycles in a single day!
| Cores | Time (h) | Speedup | Efficiency | Cells per core | Engine cycles per day |
|---|---|---|---|---|---|
| 56 | 11.51 | 1 | 100% | 12,500 | 2.1 |
| 112 | 5.75 | 2.00 | 100% | 6,200 | 4.2 |
| 224 | 3.08 | 3.74 | 93% | 3,100 | 7.8 |
| 448 | 1.91 | 6.67 | 75% | 1,600 | 12.5 |
As the world steps into a new era of sustainability, the value of a CFD solver that can accurately and efficiently model electromobility applications is increasing. CONVERGE’s HPC capabilities enable the capture of complex electrochemical processes in emobility applications, helping to identify optimal conditions for performance, lifespan, and safety. When you have the ability to run simulations on hundreds of cores, you can afford to assess extreme scenarios such as short circuits or thermal runaway through iterative testing. HPC also enables the modeling of electromagnetic fields, thermal dynamics, and mechanical stresses, leading to more accurate predictions of motor performance.




