Benefits
Events
Products & Programs


Author:
Kelly Senecal
Owner and Vice President of Convergent Science
When Eric, Keith, and I first wrote CONVERGE back in 2001, we wrote it as a serial code. That probably sounds a little crazy, since practically all CFD simulations these days are run in parallel on multiple CPUs, but that’s how it started. We ended up taking our serial code and making it parallel, which is arguably not the best way to create a parallel code. As a side effect of writing the code this way, there were inherent parts of CONVERGE that did not scale well, both in terms of speed and memory. This wasn’t a real issue for our clients who were running engine simulations on relatively small numbers of cores. But as time wore on, our users started simulating many different applications beyond IC engines, and those simulating engines wanted to run finer meshes on more cores. At the same time, computing technology was evolving from systems with relatively few cores per node and relatively high memory per core to modern HPC clusters with more cores and nodes per system and relatively less memory per core. We knew at some point we would have to rewrite CONVERGE to take advantage of the advancements in computing technology.
We first conceived of CONVERGE 3.0 around five years ago. At that point, none of the limitations in the code were significantly affecting our clients, but we would get the occasional request that was simply not feasible in the current software. When we got those requests, we would categorize them as “3.0”—requests we deemed important, but would have to wait until we rewrote the code. After a few years, some of the constraints of the code started to become real limitations for our clients, so our developers got to work in earnest on CONVERGE 3.0. Much of the core framework and infrastructure was redesigned from the ground up in version 3.0, including a new mesh API, surface and grid manipulation tools, input and output file formats, and load balancing algorithms. The resulting code enables our users to run larger, faster, and more accurate simulations for a wider range of applications.
Scalability and Shared Memory
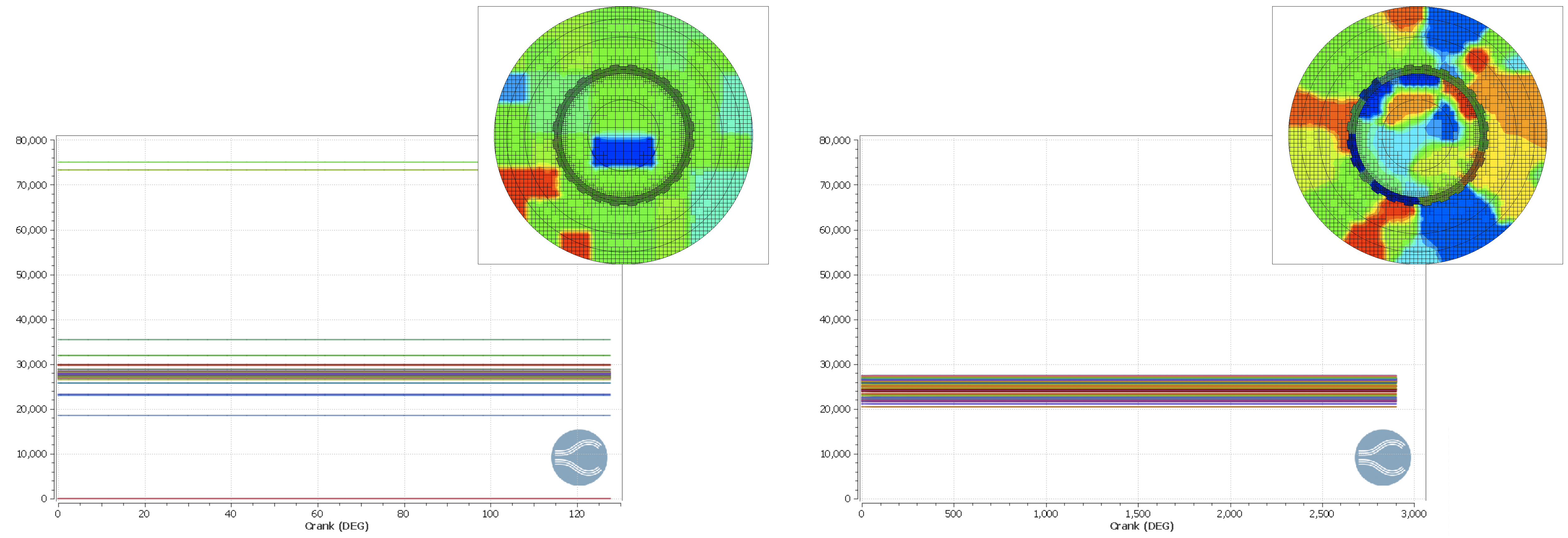
Two of our major goals in rewriting CONVERGE were to improve the scalability of the code and to reduce the memory requirements. Scaling in CONVERGE 2.x versions was limited in large part because of the parallelization method. In the 2.x versions, the simulation domain is partitioned using blocks coarser than the solution grid. This can cause a poor distribution of workload among processors if you have high levels of embedding or Adaptive Mesh Refinement (AMR). In 3.0, the solution grid is now partitioned directly, so you can achieve a good load balance even with very high levels of embedding and AMR. In addition, load balancing is now performed automatically instead of on a fixed schedule, so the case is well balanced throughout more of the run. With these changes, we’ve seen a dramatic improvement in scaling in 3.0, even on thousands of cores.

To reduce memory requirements, our developers moved to a shared memory strategy and removed redundancies that existed in previous versions of CONVERGE. For example, many data structures, like surface triangulation, that were stored once per core in the 2.x versions are now only stored once per compute node. Similarly, CONVERGE 3.0 no longer stores the entire grid connectivity on every core as was done in previous versions. The memory footprint in 3.0 is thus greatly reduced, and memory requirements also scale well into thousands of cores.
Inlaid Mesh
Apart from the codebase rewrite, another significant change we made was to incorporate inlaid meshes into CONVERGE. For years, users have been asking for the ability to add extrusion layers to boundaries, and it made sense to add this feature now. As many of you are probably aware, autonomous meshing is one of the hallmarks of our software. CONVERGE automatically generates an optimized Cartesian mesh at runtime and dynamically refines the mesh throughout the simulation using AMR. All of this remains the same in CONVERGE 3.0, and you can still use meshes exactly as they were in all previous versions of CONVERGE! However now we’ve added the option to create an inlaid mesh made up of cells of arbitrary shape, size, and orientation. The inlaid mesh can be extruded from a triangulated surface (e.g., a boundary layer) or it can be a shaped mesh away from a surface (e.g., a spray cone). For the remainder of the domain not covered by an inlaid mesh, CONVERGE uses our traditional Cartesian mesh technology.
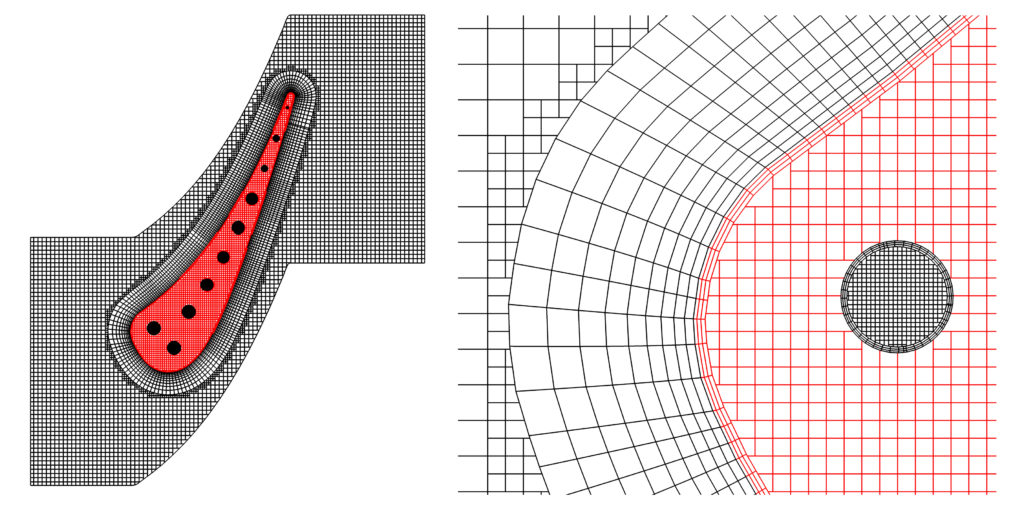
Inlaid meshes are always optional, but in some cases they can provide accurate results with fewer cells compared to a traditional Cartesian mesh. In the example of a boundary layer, you can now refine the mesh in only the direction normal to the surface, instead of all three directions. You can also align an inlaid mesh with the direction of the flow, which wasn’t always possible when using a Cartesian mesh. This feature makes CONVERGE better suited for certain applications, like external aerodynamics, than it was previously.
Combustion and Chemistry
In CONVERGE 3.0, our developers have also enhanced and added to our combustion models and chemistry tools. For the SAGE detailed chemistry solver, we optimized the rate calculations, improved the procedure to assemble the sparse Jacobian matrix, and we introduced a new preconditioner. The result is significant speedup in the chemistry solver, especially for large reaction mechanisms (>150 species). If you thought our chemistry solver was fast before (and it was!), you will be amazed at the speed of the new version. In addition, 3.0 features two new combustion models. In most large eddy simulations (LES) of premixed flames, the cells are not fine enough to resolve the laminar flame thickness. The thickened flame model for LES allows you to increase the flame thickness without changing the laminar flamespeed. The second new model, the SAGE three-point PDF model, can be used to account for turbulence-chemistry interaction (more specifically, the commutation error) when modeling turbulent combusting flows with RANS.
On the chemistry tools side, we’ve added a number of new 0D chemical reactors, including variable volume with heat loss, well-stirred, plug flow, and 0D engine. The 1D laminar flamespeed solver has seen significant improvements in scalability and parallelization, and we have new table generation tools in CONVERGE Studio for tabulated kinetics of ignition (TKI), tabulated laminar flamespeed (TLF), and flamelet generated manifold (FGM).
CONVERGE Studio Updates
To streamline our users’ workflow, we have implemented several updates in CONVERGE Studio, CONVERGE’s graphical user interface (GUI). We partnered with Spatial to allow users to directly import CAD files into CONVERGE Studio 3.0, and triangulate the geometry on the fly in a way that’s optimized for CONVERGE. Additionally, Tecplot for CONVERGE, CONVERGE’s post-processing and visualization software, can now read CONVERGE output files directly, for a smoother workflow from start to finish.
CONVERGE 3.0 was a long time in the making, and we’re very excited about the new capabilities and opportunities this version offers our users. 3.0 is a big step towards CONVERGE being a flexible toolbox for solving any CFD problem.
[1] The National Center for Supercomputing Applications (NCSA) at the University of Illinois at Urbana-Champaign provides supercomputing and advanced digital resources for the nation’s science enterprise. At NCSA, University of Illinois faculty, staff, students, and collaborators from around the globe use advanced digital resources to address research grand challenges for the benefit of science and society. The NCSA Industry Program is the largest Industrial HPC outreach in the world, and it has been advancing one third of the Fortune 50® for more than 30 years by bringing industry, researchers, and students together to solve grand computational problems at rapid speed and scale. The CONVERGE simulations were run on NCSA’s Blue Waters supercomputer, which is one of the fastest supercomputers on a university campus. Blue Waters is supported by the National Science Foundation through awards ACI-0725070 and ACI-1238993.







