Benefits
Events
Products & Programs


Author:
Sankalp Lal
Application Engineer, Documentation and Technical Marketing
In a competitive market, predictive computational fluid dynamics (CFD) can give you an edge when it comes to product design and development. Not only can you predict problem areas in your product before manufacturing, but you can also optimize your design computationally and devote fewer resources to testing physical models. To get accurate predictions in CFD, you need to have high-resolution grid-convergent meshes, detailed physical models, high-order numerics, and robust chemistry—all of which are computationally expensive. Using simulation to expedite product design works only if you can run your simulations in a reasonable amount of time.
The introduction of high-performance computing (HPC) drastically furthered our ability to obtain accurate results in shorter periods of time. By running simulations in parallel on multiple cores, we can now solve cases with millions of cells and complicated physics that otherwise would have taken a prohibitively long time to complete.
However, simply running cases on more cores doesn’t necessarily lead to a significant speedup. The speedup from HPC is only as good as your code’s parallelization algorithm. Hence, to get a faster turnaround on product development, we need to improve our parallelization algorithm.
Breaking a problem into parts and solving these parts simultaneously on multiple interlinked processors is known as parallelization. An ideally parallelized problem will scale inversely with the number of cores—twice the number of cores, half the runtime.
A common task in HPC is measuring the scalability, also referred to as scaling efficiency, of an application. Scalability is the study of how the simulation runtime is affected by changing the number of cores or processors. The scaling trend can be visualized by plotting the speedup against the number of cores.
In CONVERGE versions 2.4 and earlier, parallelization is performed by partitioning the solution domain into parallel blocks, which are coarser than the base grid. CONVERGE distributes the blocks to the interlinked processors and then performs a load balance. Load balancing redistributes these parallel blocks such that each processor is assigned roughly the same number of cells.
This parallel-block technique works well unless a simulation contains high levels of embedding (regions in which the base grid is refined to a finer mesh) in the calculation domain. These cases lead to poor parallelization because the cells of a single parallel block cannot be split between multiple processors.
Figure 1 shows an example of parallel block load balancing for a test case in CONVERGE 2.4. The colors of the contour represent the cells owned by each processor. As you can see, the highly embedded region at the center is covered by only a few blocks, leading to a disproportionately high number of cells in those blocks. As a result, the cell distribution across processors is skewed. This phenomenon imposes a practical limit on the number of levels of embedding you can have in earlier versions of CONVERGE while still maintaining a reasonable load balance.

In CONVERGE 3.0, instead of generating parallel blocks, parallelization is accomplished via cell-based load balancing, i.e., on a cell-by-cell basis. Because each cell can belong to any processor, there is much more flexibility in how the cells are distributed, and we no longer need to worry about our embedding levels.
Figure 2 shows the cell distribution among processors using cell-based load balancing in CONVERGE 3.0 for the same test case shown in Figure 1. You can see that without the restrictions of the parallel blocks, the cells in the highly embedded region are divided between many processors, ensuring an (approximately) equal distribution of cells.

The cell-based load balancing technique demonstrates significant improvements in scaling, even for large numbers of cores. And unlike previous versions, the load balancing itself in CONVERGE 3.0 is performed in parallel, accelerating the simulation start-up.
In order to see how well the cell-based parallelization works, we have performed strong scaling studies for a number of cases. The term strong scaling means that we ran the exact same simulation (i.e., we kept the number of cells, setup parameters, etc. constant) on different core counts.
Figure 3 shows scaling results for a typical SI8 port fuel injection (PFI) engine case in CONVERGE 3.0. The case was run for one full engine cycle, and the core count varied from 56 to 448. The plot compares the speedup obtained running the case in CONVERGE 3.0 with the ideal speedup. With enough CPU resources, in this case 448 cores, you can simulate one engine cycle with detailed chemistry in under two hours—which is three times faster than CONVERGE 2.4!

| Cores | Time (h) | Speedup | Efficiency | Cells per core | Engine cycles per day |
|---|---|---|---|---|---|
| 56 | 11.51 | 1 | 100% | 12,500 | 2.1 |
| 112 | 5.75 | 2 | 100% | 6,200 | 4.2 |
| 224 | 3.08 | 3.74 | 93% | 3,100 | 7.8 |
| 448 | 1.91 | 6.67 | 75% | 1,600 | 12.5 |
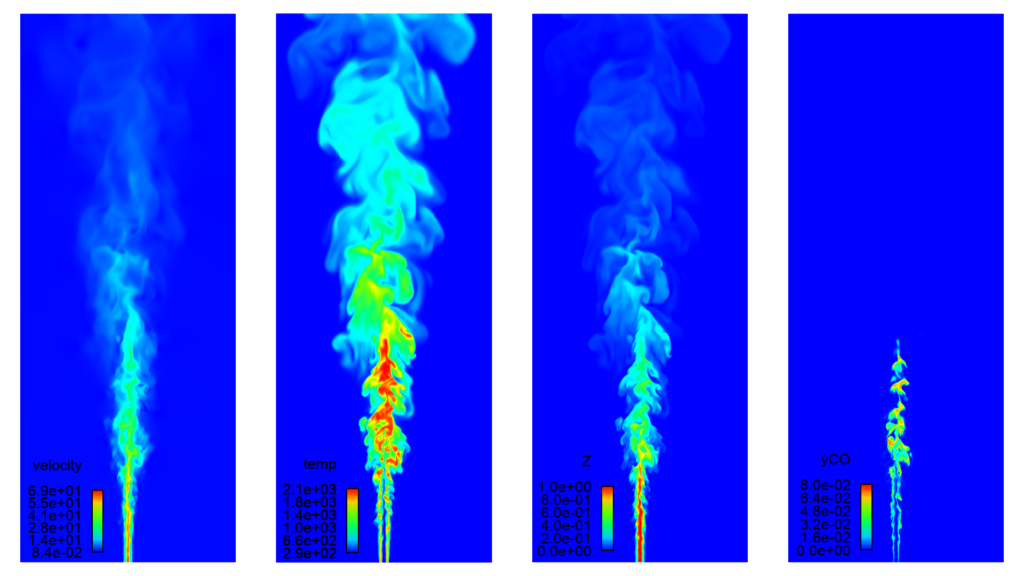
If the speedup of the SI8 PFI engine simulation impressed you, then just wait until you see the scaling study for the Sandia Flame D case! Figure 4 shows the results of a strong scaling study performed for the Sandia Flame D case, in which we simulated a methane flame jet using 170 million cells. The case was run on the Blue Waters supercomputer at the National Center for Supercomputing Applications (NCSA), and the core counts vary from 500 to 8,000. CONVERGE 3.0 demonstrates impressive near-linear scaling even on thousands of cores.

Although earlier versions of CONVERGE show good runtime improvements with increasing core counts, speedup is limited for cases with significant local embeddings. CONVERGE 3.0 has been specifically developed to run efficiently on modern hardware configurations that have a high number of cores per node.
With CONVERGE 3.0, we have observed an increase in speedup in simulations with as few as approximately 1,500 cells per core. With its improved scaling efficiency, this new version empowers you to obtain simulation results quickly, even for massive cases, so you can reduce the time it takes to bring your product to market.
Contact us to learn how you can accelerate your simulations with CONVERGE 3.0.
[1] The National Center for Supercomputing Applications (NCSA) at the University of Illinois at Urbana-Champaign provides supercomputing and advanced digital resources for the nation’s science enterprise. At NCSA, University of Illinois faculty, staff, students, and collaborators from around the globe use advanced digital resources to address research grand challenges for the benefit of science and society. The NCSA Industry Program is the largest Industrial HPC outreach in the world, and it has been advancing one third of the Fortune 50® for more than 30 years by bringing industry, researchers, and students together to solve grand computational problems at rapid speed and scale. The CONVERGE simulations were run on NCSA’s Blue Waters supercomputer, which is one of the fastest supercomputers on a university campus. Blue Waters is supported by the National Science Foundation through awards ACI-0725070 and ACI-1238993.







